引言
无监督学习
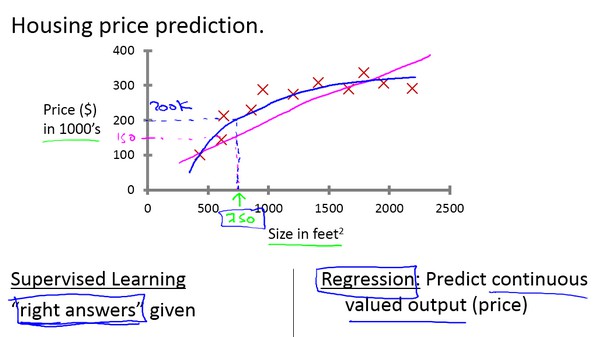
回归问题
对于房价的预测,可以采用直线拟合和二次方程拟合等方式,离散数据拟合为连续数据,是属于回归问题。
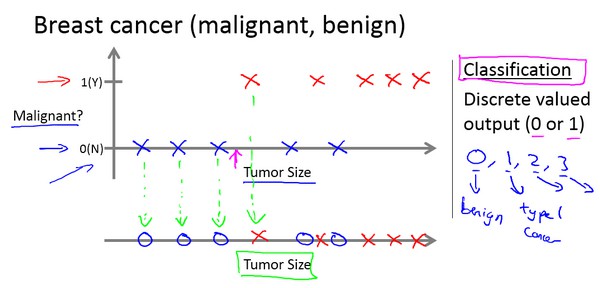
分类问题
对于判断肿瘤是否为良性,良性为0,恶性为1,或者良性为0,还有1类恶性,2类恶性,3类恶性等等,这属于分类问题。
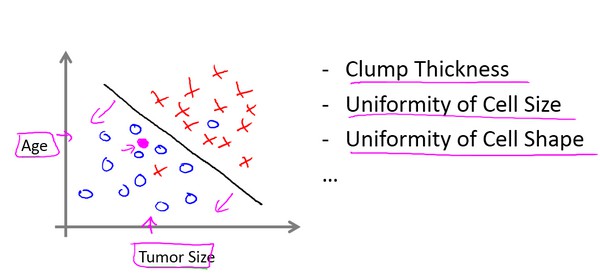
SVM支持向量机
在其他一些机器学习问题中,可能会遇到不止一种特征。举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄。在其他机器学习问题中,我们通常有更多的特征,比如肿块的密度、肿瘤细胞的尺寸的一致性和形状的一致性等等。
这类多特征的问题可以用SVM支持向量机来处理。
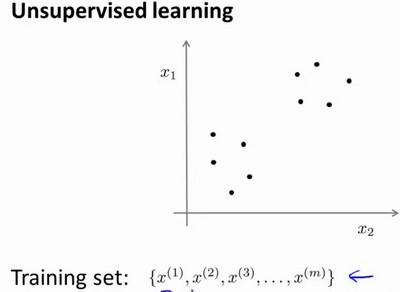
无监督学习
监督学习的数据集都已经被标明是阴性或阳性。所以对监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案。然而,在无监督学习中没有任何标签。
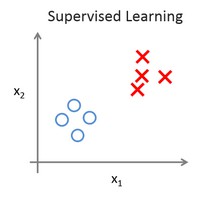
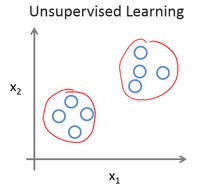
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇,这种算法叫做聚类算法。
开发环境
-
安装anaconda包,其中包含大量的科学计算包,其中就包含ipython和jupyter,安装之后即可用其打开ipython文件。
-
在终端中输入:jupyter notebook
-
然后就可以在浏览器中打开pynb文件
单变量线性回归
模型表示
单变量线性回归,即Linear Regression with One Variable。
我们将用来描述回归问题的变量定义如下:
- $m$代表训练集中实例的数量
- $x$代表特征/输入变量
- $y$代表目标变量/输出变量
- $(x,y)$代表训练集中的实例
- $(x^{(i)},y^{(i)})$代表第$i$个观察实例
- $h$代表学习算法的解决方案或假设模型
因为只含有一个特征/输入变量,所以单变量线性回归问题可表示为:
代价函数
我们选择的参数$\theta_{0}$和$\theta_{1}$决定了训练集的准确程度,模型所预测的值与实际值之间的差距就是建模误差。
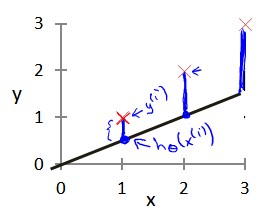
我们的目标就是寻找可以使得建模误差的平方和最小的模型参数。代价函数为:
绘制一个等高线图,三个坐标分别为$\theta_{0}$和$\theta_{1}$以及$J(\theta_{0},\theta_{1})$:
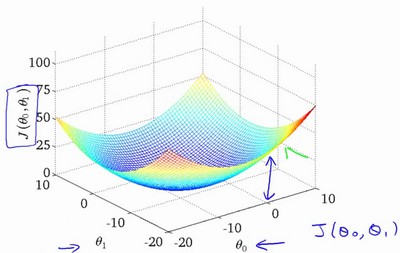
则可以看出三维空间中存在一个使得代价最小的点。
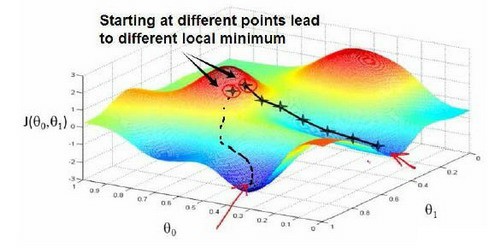
梯度下降
梯度下降的思想是:开始时我们随机选择一个参数的组合$(\theta_{0},\theta_{1},…,\theta_{n})$,计算代价函数,然后我们寻找下一个能让代价函数南湖值下降最多的参数组合。我们持续这么做直到得到一个局部最小值。因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的是否是全局最小值。
梯度下降算法公式为:

其中$\alpha$为学习率,他决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
注意:先计算$\theta_{0}$和$\theta_{1}$,再同时更新。
多变量线性回归
多变量线性回归,即Linear Regression with Multiple Variable。
多维特征
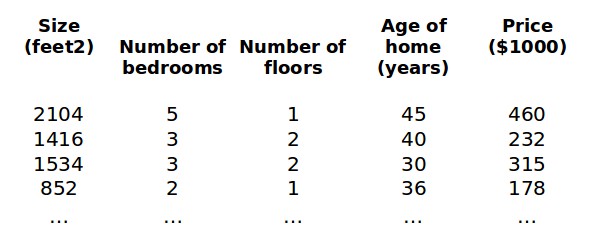
对于多维特征,我么引入一些新的说明:
- $n$代表特征的数量
- $x^{(i)}$代表第$i$个训练实例,是特征矩阵中的第$i$行。
- $x_{j}^{(i)}$代表特征矩阵中的第$i$行的第$j$个特征。
如上图的$x_{2}^{(2)}=3$,$x_{3}^{(2)}=2$。多变量的假设$h$表示为:
为了使公式简化,令$x_{0}=1$:
多变量梯度下降
代价函数
在多变量线性回归中,我们也构建一个代价函数:
梯度下降
在多变量线性回归中,梯度下降算法与单变量类似,只不过$(j=0,1,…,n)$。
特征缩放
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助算法更快的收敛。
以房价问题为例,假设我们使用两个特征,房屋尺寸和房间的数量,尺寸的值为0-2000平方英尺,而房间数量的值则为0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图,能看出图像很扁,梯度下降算法需要非常多次的迭代才能收敛。
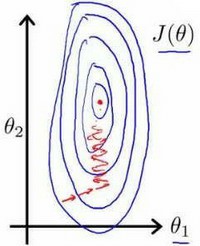
解决办法是尝试将所有特征的尺度都尽量缩放到-1到1之间,如图:
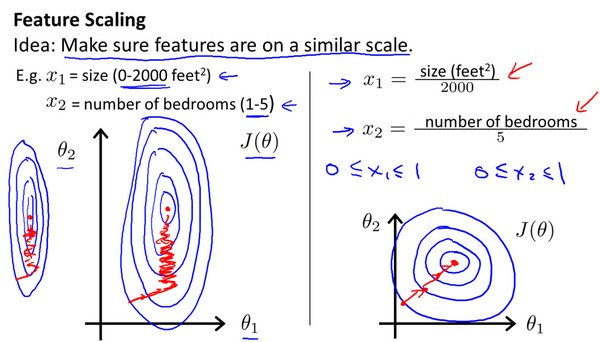
最简单的方法是令$x_{n}=\frac{x_{n}-\mu_{n}}{s_{n}}$,其中$\mu_{n}$是标准差。
学习率
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时区域收敛。
也有一些自动测试是否收敛的方法,例如将代价函数的变化值与一个阈值进行比较。
特征和多项式回归
线性回归并不适用于所有的数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型或者三次方模型。
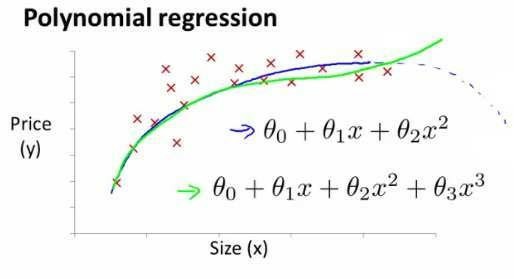
注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
正规方程
都目前为止,我们都在使用梯度下降算法,但是对于某些线性回归问题,正规方程方法是更好的解决方案。如:
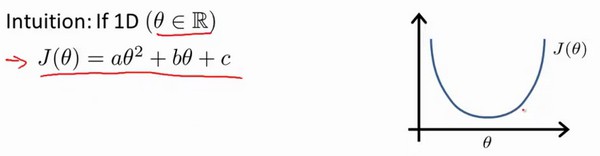
正规方程时通过偏导为0来使得代价函数最小。
假设我们的训练集特征矩阵为$X$(包含了$x_{0}=1$),并且我们的训练集结果为向量$y$,,则利用正规方程解出向量$\theta=(X^{T}X^{-1}X^{T}y)$。
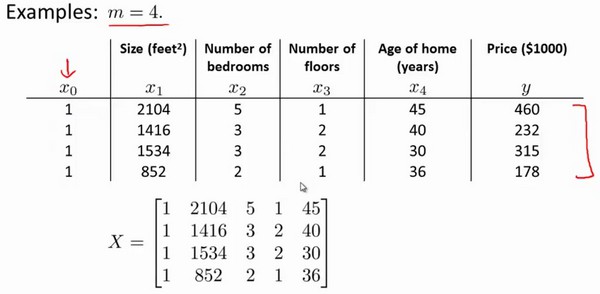
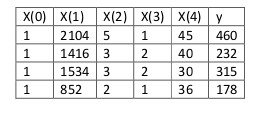
运用正规方程方法求解参数:
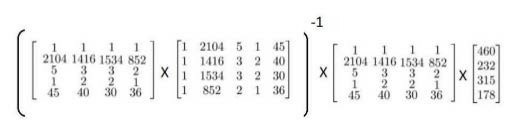
注:对于不可逆的矩阵,正规方程方法是不可用的。
| 梯度下降 | 正规方程 |
| 需要选择学习率$\alpha$ | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量n大时也适用 | 求逆算法大 |
| 适用于各种模型 | 只适合线性,不适合逻辑回归等其他 |
注:只要特征数量n小于10000,通常使用正规方程的方法。对于特定的线性方程,更快。
对于不可逆的情况,可以使用正则化的方法,通过删除某些特征(线性相关的特征),来解决不可逆的问题。
逻辑回归
分类问题
逻辑回归:输出值永远在0-1之间,即:$0 \le h_{\theta(x)} \le 1$。
假说表示
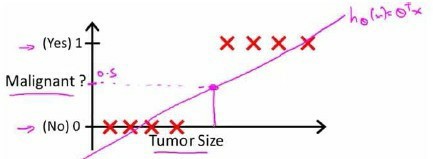
对于线性回归来说,当$h_{\theta} \ge 0.5$时,$y=1$,否则$y=0$。当一个$x$轴特征比较大的反例,则会被预测为良性,所以线性回归不适合解决这类问题。
逻辑回归模型:
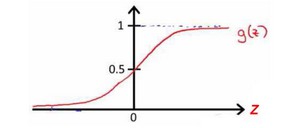
其中,X代表特征向量,$g$代表逻辑函数sigmoid函数,$g(z)=\frac{1}{1+e^{-z}}$。
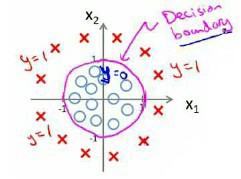
判定边界
假设有一模型:
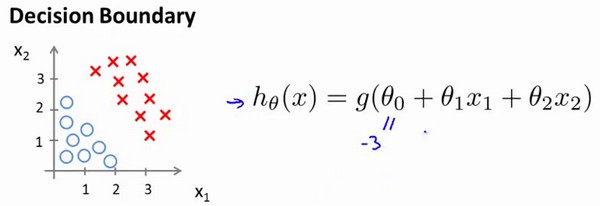
参数$\theta$为向量[-3 1 1],则当$-3+x_{1}+x_{2} \ge 0$时,模型输出1。我们可以绘制直线$x_{1}+x_{2}=3$,这条直线便是分界线。
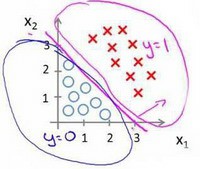
对于如下情况,需要采用二次方程等模型:
代价函数
我们将$h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T}X}}$带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数:
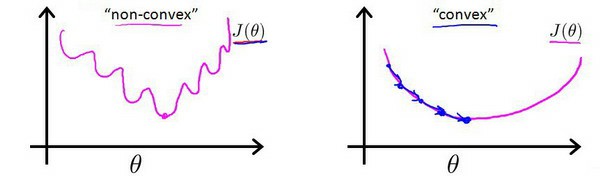
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
我们定义逻辑回归的代价函数为:
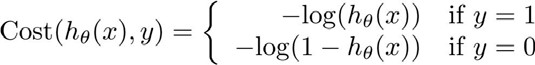
$h_{\theta}(x)$与$Cost(h_{\theta}(x),y)$之间的关系如下:
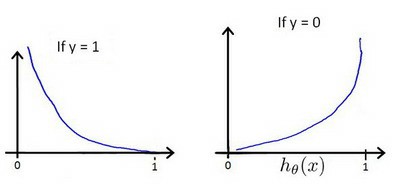
得到逻辑回归的代价函数:
注:逻辑回归的假设函数与线性回归的假设函数不一样:
-
线性回归:$h_{\theta}(x)=\theta_{0}x_{0}+\theta_{1}x_{1}+…$
-
逻辑函数:$h_{\theta}(x)= \frac{1}{1+e^{-\theta^{T}X}}$
高级优化
梯度下降并不是我们可以使用的唯一算法,比如共轭梯度算法、BFGS(变尺度法)和L-BFGS(限制变尺度法)。
多类别分类:一对多
对于一个多类分类问题,我们的数据集或许看起来像这样:
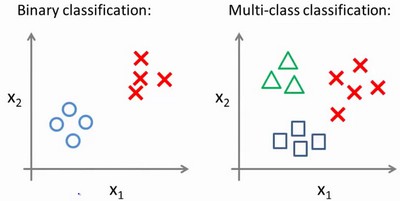
首先假设三角形为正样本,可以得到一个逻辑回归分类;然后把正方形作为正样本又可以得到一个分类;再把叉叉作为正样本,又可以得到一个。
最后得到的模型简单记为:
其中,$i=(1,2,3)$。
我们要做的就是在三个分类器里面输入一个$x$,选择一个让$h_{\theta}^{i}(x)$最大的$i$。
正则化
过拟合
对于下面的回归问题,第一个模型是一个线性模型,属于 欠拟合 。第三个模型是一个四次方的模型,过度强调拟合原始数据,而丢失了算法的本质,预测新数据表现差,属于 过拟合 。而中间的模型似乎最合适。
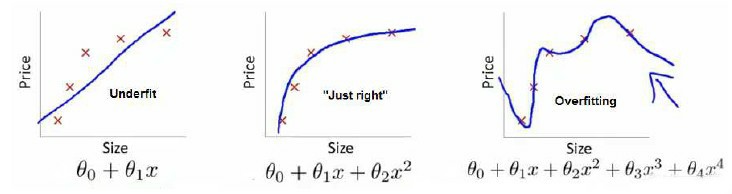
对于多项式的理解,次数越高,拟合的越好,但相应的预测能力就可能变差。
对于分类问题也存在这样的问题:
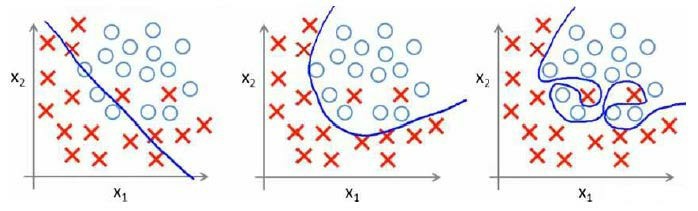
解决过拟合问题:
-
丢弃一些不能帮助我们正确预测的特征,可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(如:PCA)。
-
正则化:保留所有的特征,但是减少参数的大小。
代价函数
假设上面的回归问题模型为:$h_{\theta}(x)=\theta_{0}+\theta_{1}x_{1}+…$。我们可以从之前的事例可以看出,正是那些高次项导致了过拟合,所以如果我们能让这些高次项的系数接近0的话,我们就能很好的拟合了。
所以我们要做的就是在一定程度上减小这些参数$\theta$的值,这就是正则化的基本思想。我们要减小$\theta_{3}$和$\theta_{4}$的大小,我们要做的就是修改代价函数,在$\theta_{3}$和$\theta_{4}$设置一点惩罚,并最终导致选择较小的$\theta_{3}$和$\theta_{4}$,修改过的代价函数如下:
假如我们有非常多的特征,并不知道其中哪些特征需要惩罚,我们将对所有的特征进行惩罚:
其中,$\lambda称为正则化系数$。一般不对$\theta_{0}$进行惩罚,正则化的模型与原模型比较为:
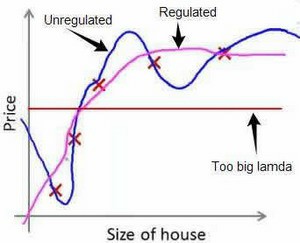
如果选择的参数过$\lambda$过大,则会把所有的参数都最小化,则模型变为$h_{\theta}(x)=\theta_{0}$,如图中棕色线所示。
正则化线性回归
对于线性回归的求解没我们之前推导了两种学习算法:一种基于梯度下降,一种基于正规方程。
正则化的线性回归的代价函数为:
梯度下降法如下:
正规方程法如下:
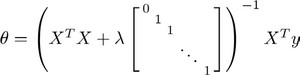
图中的矩阵尺寸为(n+1)x(n+1)
正则化逻辑回归
针对逻辑回归,我们之前学了两种优化算法:梯度下降和高级的优化算法。
正则化的代价函数:
正则化的梯度:
注:参数$\theta_{0}$的更新规则与其他情况不同。
神经网络
神经网络,即Neural Networks。
非线性假设
我们之前学过,无论是线性回归还是逻辑回归都有这样一个缺点:当特征太多时,计算的负荷会非常大,如下图:
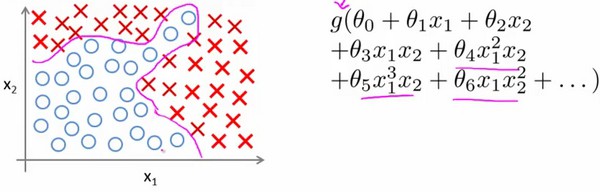
模型表示
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为3层的神经网络,第一层为输入错,最后一层为输出层,中间一层为隐藏层,我们为每一层都增加一个偏差单位。
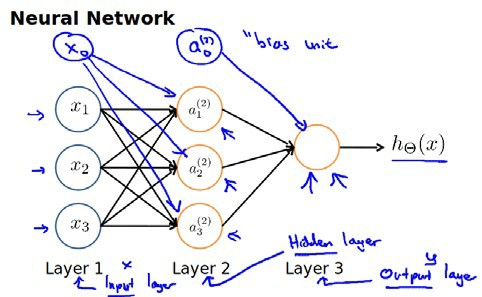
$a_{i}^{(j)}$代表第$j$个激活单元。$\theta^{j}$代表从第$j$层映射到第$j+1$层时的权重的矩阵,例如$\theta^{(1)}$代表从第一层映射到第二层的权重的矩阵。其尺寸为:以第$j+1$层的激活单元数量为行数,以第$j$层的激活单元数加一为列数的矩阵。上图的神经网络中$\theta^{(1)}$的尺寸为3x4。
前向传播
多分类
当我们要识别人、汽车、摩托和卡车,则在输出层应该有4个值。输出层应会出现$[a b c d]^T$,且$a,b,c,d$中仅有一个为1,表示当前类。
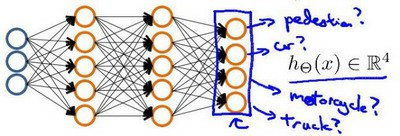
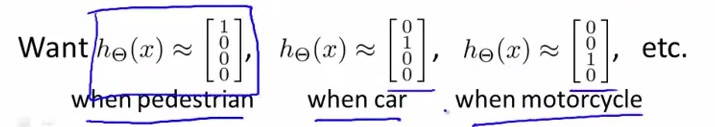
神经网络输出为四种可能性:

代价函数
假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络层数,$S_{l}$表示每层的neuron各个最后一层中的处理单元的个数。将神经网络的分类定义为两种情况:二类分类和多类分类:
-
二类分类:$S_{L}=0,y=0 or 1$表示哪一类
-
K类分类:$S_{L}=k,y_{i}=1$表示分到第$i$类
代价函数为:
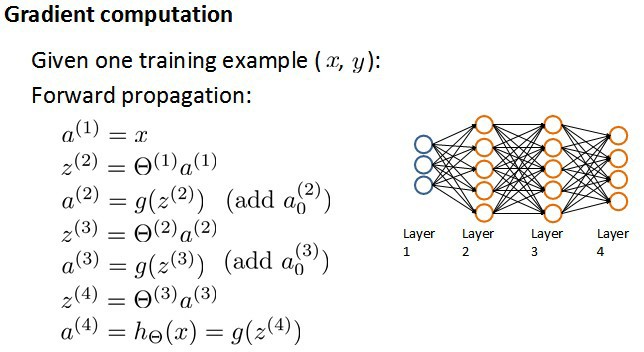
反向传播
为了计算代价函数的偏导数,我们需要采用一种反向传播的算法,也就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。以
假设我们的训练集只有一个实例$(x^{(1)},y^{(1)})$,我们的神经网络是一个四层的神经网络,其中$K=4,S_L=4,L=4$。
我们从最后一层的误差开始计算,误差是激活单元的预测$(a_{k}^{(4)})$与实际值$(y^{k})$之间的误差,$(k=1:k)$。
我们用$\delta$表示误差,则$\delta^{(4)}=a^{(4)}-y$。
我们利用这个误差来计算前一层的误差:
其中,${g}’(z^{(3)})$为S型函数的导数,${g}’(z^{(3)})=a^{(3)}*(1-a^{(3)})$。
-
$l$表示目前计算的第几层
-
$j$代表目前计算层中的激活单元的下标,也将是下一层的第$j$个输入变量的下标
-
$i$代表下一层中误差单元的下标,是受到权重矩阵中第$i$行影响的下一层中的误差单元的下标
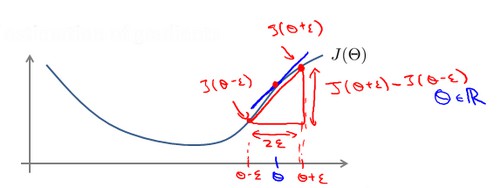
梯度检验
神经网络使用梯度下降时,得到的最终结果可能不是最优解。为了解决这样的问题,我们采用梯度检测的办法。
在代价函数上沿着切线的方向选择离两个非常近的点,然后计算两个点的平均值,用以估计梯度。即对于某个特定的$\theta$,我们计算$\theta-\epsilon$和$\theta+\epsilon$处的代价值,然后取平均用以估计此点的代价。
随机初始化
任何优化算法都需要一些初始化的参数。都目前为止我们都是初始化所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。我们通常初始化参数为正负$\epsilon$之间的随机值,假设我们要随机初始一个尺寸为10x11的参数矩阵,代码如下:
Theta1 = rand(10,11)*(2*eps)-eps
算法步骤
训练神经网络的算法步骤:
-
参数的随机初始化
-
利用正向传播方法计算所以的$h_{\theta}(x)$
-
编写计算代价函数$J$的代码
-
利用反向传播方法计算所有偏导数
-
利用数值检验方法检验这些偏导数
-
使用优化算法来最小化代价函数
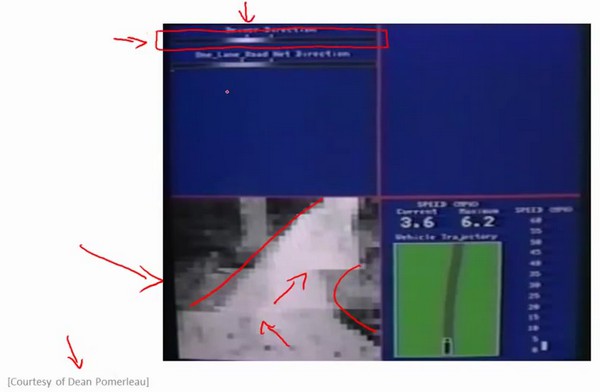
自动驾驶
白亮的区域显示的就是神经网络在这里选择的行驶方向,是稍微的左转,并且实际上在神将网络开始学习之前,你会看到网络的输出是一条灰色的区域,就这就是神经网络已经随机初始化了,并且在初始化时,我们并不知道汽车如何行驶。只有在学习算法运行了足够长的时间之后,才会有这条白色的区域出现在整条灰色区域之中。
还可以多个神经网络同时工作每个网络都生成一个行驶方向,以及一个预测自信度的参数,预测自信度最高的那个神经网络得到最终行驶方向。
应用建议
下一步做什么
假如在预测过程中产生了很大的误差,怎么办?
-
使用更多的训练样本(不一定能改善)
-
尝试选用更少的特征集,挑选精确的部分特征,防止过拟合
-
寻找更多的有用特征
-
尝试增加多项式特征
-
尝试减少/增加正则化程度$\lambda$
评估假设
最小的训练误差不代表训练出来的假设函数是最好的!可能过拟合。
判断过拟合
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常70%的数据作为训练集,用剩下的作为测试集。很重要的一点是训练集合测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集合测试集。
把训练出的模型运用与测试集:
-
对于线性回归,可以计算代价函数
-
对于逻辑回归,除了计算代价函数,还可以计算误差:
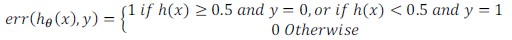
然后对计算结果进行平均。
模型选择和交叉验证集
假如有10个不同次数的二项式模型可供选择:
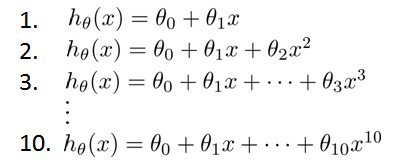
显然次数越高的多项式模型越能适应我们的训练集,但是可能过拟合。我们需要使用交叉验证集来帮助选择模型。
即:使用60%的数据作为训练集,使用20%的数据作为交叉验证集,使用20%的数据作为测试集。
-
使用训练集训练出10个模型
-
用10个模型分别对交叉验证集计算交叉验证误差$J_{cv}(\theta)$(代价函数的值)
-
选取代价函数值最小的模型
-
用步骤3中选取的模型对测试集计算得到推广误差$J_{test}(\theta)$(代价函数的值)
方差和偏差
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差(bias)比较大,要么是方差(variance)比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合。
通常会将训练集合交叉训练集的代价函数误差与多项式的次数绘制在同一张图表上分析:
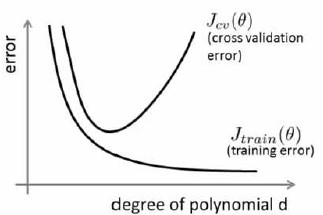
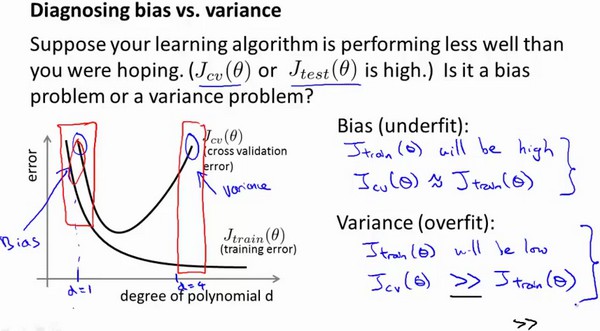
结论:
-
训练集误差和交叉验证集误差近似时:偏差/欠拟合
-
交叉验证集误差远大于训练集误差时:方差/过拟合
正则化和偏差/方差
选择$\lambda$的方法:
-
使用训练集训练出12个不同程度正则化的模型
-
用12个模型分别对交叉验证集计算出的交叉验证集误差
-
选择得出交叉验证误差最小的模型
-
运用步骤3中选出模型对测试集计算的出推广误差
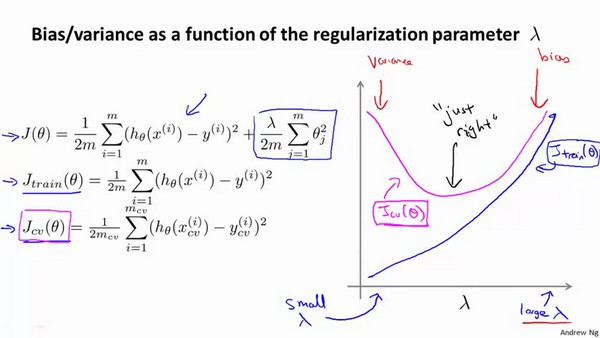
-
当$\lambda$较小时,训练集误差较小,过拟合,方差
-
当$\lambda$较大时,训练集误差不断增加,欠拟合,偏差
学习曲线
学习曲线就是一种很好的工具,我们经常使用学习曲线来判断某个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验。学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表。
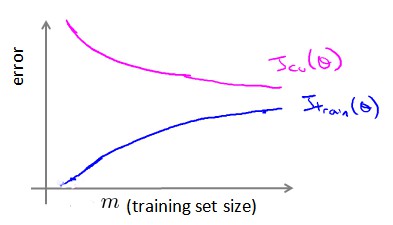
由上图可以看出,在高方差/过拟合的情况下,增加更多的训练集可能提高算法效果。
-
获得更多的训练集—解决高方差
-
减少特征数量—解决高方差
-
获得更多的特征—解决高偏差
-
增加多项式特征—解决高偏差
-
减少正则化程度$\lambda$—解决高偏差
-
增加正则化程度$\lambda$—解决高方差
机器学习系统设计
接下来将设计一个垃圾邮件分类器系统。
为了解决这一问题,我们首先要做的是如何选择并表达特征向量$x$。我们可以选择由100个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,以此来获得我们的特征向量(出现为1,不出现为0),尺寸为100x1。
为了构建这个分类器算法,我们可以做很多事:
-
收集更多的数据,让我们有更多的分类样本
-
基于邮件的路由信息开发一系列复杂的特征
-
基于邮件的正文信息开发一系列复杂的特征(截取)
-
为探测刻意的拼写错误开发复杂的算法
误差分析
当你研究机器学习问题的时候,最初可以不用复杂的系统,先把结果跑出来,然后用交叉验证检验数据,画出 学习曲线 ,以检验误差。除了画学习曲线之外,还有一件非常有用的事是 误差分析 。你会发现某些系统性的规律,什么类型的邮件总是被错误分类,然后构造新的特征,去优化系统。
-
快速训练算法
-
交叉验证
-
绘制学习曲线
-
误差分析
偏斜类的误差度量
偏斜类表现为我们的训练集中有非常多的同一类的实例,为反例很少或者没有。
- 正确肯定(TP),预测为真,实际为真
- 正确否定(TN),预测为假,实际为假
- 错误肯定(FP),预测为真,实际为假
- 错误否定(FN),预测为假,实际为真
-
查准率Presision=TP/(TP+FP)。在预测没病的病人中,实际上没病的百分比越高越好
-
查全率Recall=TP/(TP+FN)。在没病的病人中,成功被预测没病的百分比越高越好
查准率和查全率往往是矛盾的。可以通过大阈值来增大查准率,但会降低查全率。
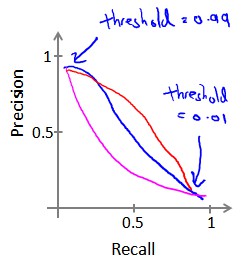
通过如下F1的值来权衡查准率和查全率(越高越好):
支持向量机
支持向量机,即:support vector machine,也是一种监督学习算法。
优化目标
由逻辑回归到SVM:
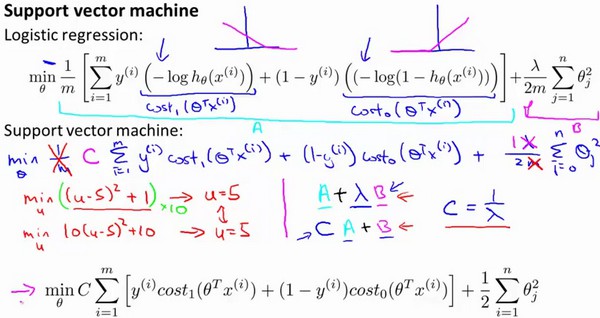
C为常数。
直观理解

支持向量机将会选择这个黑色的决策边界,相较于粉色或者绿色的决策界,黑色更好。支持向量机有时被称为大间距分类器。
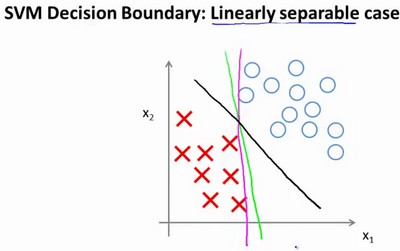
$C=1/\lambda$
-
C较大时,相当于$\lambda$较小时,可能会导致过拟合,高方差
-
C较小时,相当于$\lambda$较大时,可能会导致低拟合,高偏差
核函数
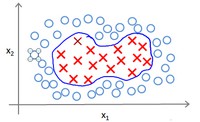
为了获得上图所示的边界,我们的模型可能是:
我们可以用一系列的新的特征f来替换模型中的每一项:$f_1=x_1,f_2=x_2,f_3=x_1x_2,f_4=x_1^2,f_5=x_2^2$
如果使用高斯核函数,需要进行特征缩放。
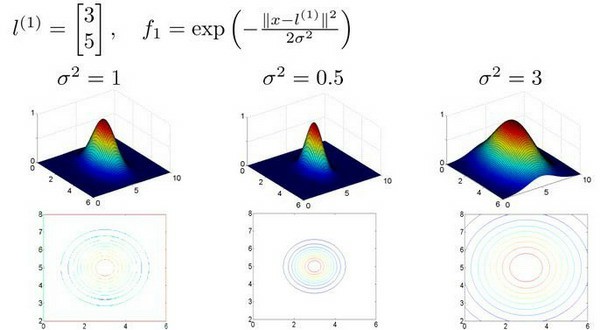
-
$\sigma$较大时,可能会导致低方差,高偏差
-
$\sigma$较小时,可能会导致低偏差,高方差
用以解决SVM最优化问题的库有很多,比如liblinear和libsvm。
普遍准则
n为特征数,m为训练样本数。
-
n»m,即训练集数据量不够支持训练一个复杂的非线性模型,我们选用逻辑回归或者不带核函数的支持向量机。
-
n较小,m大小中等,例如n在1-1000之间,而m在10-10000之间,使用高斯核函数的支持向量机。
-
m»n,例如n在1-1000之间,m大于50000,则使用支持向量机会非常慢,选用逻辑回归或者不带核函数的支持向量机。
如今的SVM包会工作得很好,但是它们仍然会有一些慢。当有非常大的训练集,且用高斯核函数是在这种情况下,我们经常会做的是尝试手动地创建,拥有更多的 特征变量 ,然后用逻辑回归或者不带核函数的支持向量机。
神经网络训练起来非常慢。
聚类
聚类属于非监督学习算法,要让计算机学习无标签数据。在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
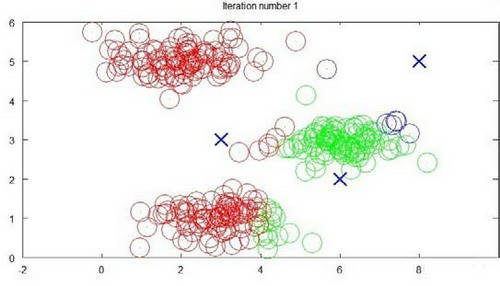
k-means算法
k-means是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组,是一种迭代算法。假设将数据聚类成n组,步骤为:
-
首先选择k个随机的点,称为
聚类中心 -
对于数据集中的每一个数据,按照距离k个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
-
计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置
-
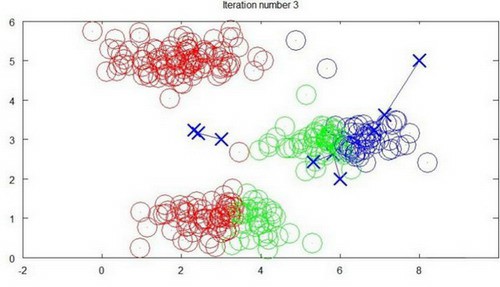
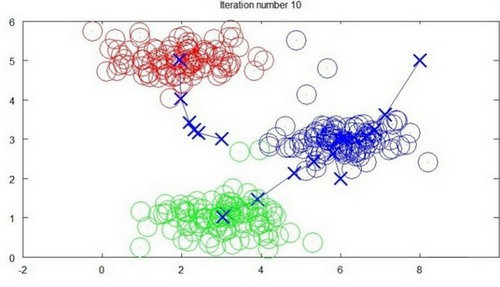
重复步骤2-4,直到中心点不再变化为止
迭代1次:
迭代3次:
迭代10次:
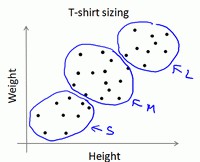
下图所示的数据集包含身高和体重两项特征,利用k-means算法将数据分为3类,用于帮助确定T恤衫的尺寸:
优化目标
k-means最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离和,因此k-means的代价函数(畸变函数)为:
其中$u_{c^{(i)}}$代表与$x^{(i)}$最近的聚类中心点。优化目标是找出使得代价函数最小的$c^{(1)},c^{(2)}…$和$u_1,…,u_k$。
在迭代算法中,第一个循环是用于减少$c$引起的代价,第二个循环是用于减少$u$引起的代价。
随机初始化
在运行k-means算法之前,需要随机初始化所有的聚类中心点:
-
应该选择k < m,即聚类中心点的个数要小于所有训练集实例的数量
-
随机选择k个训练实例,然后令k个聚类中心分别与这k个训练实例相等
k-means的问题在于,有可能会停留在一个局部最小值处,而这取决于初始化的情况。
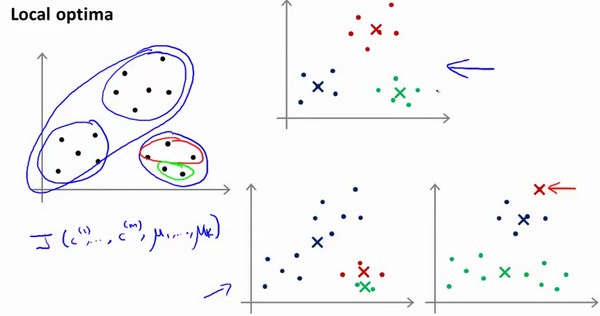
为了解决这个问题,我们通常需要多次运行k-means算法,每一次都重新进行随机初始化,最后再比较多次运行k-means的结果,选择代价函数最小的结果。这种方法在k较小的时候还是可行的,但在k较大时也不能明显地改善。
选择聚类数
改变k值,计算代价函数J,一般选取从某一k值以后,代价函数变化变缓的k值为桔聚类数。
降维
降维的目的
- 数据压缩
- 数据可视化:降维至2D-3D可视化
主成分分析PCA
主成分分析,即principal component analysis,是常见的降维算法。
在PCA中,将数据投影到一个方向向量上,使得投影平均均方误差尽可能地小。
比如从n维降到k维:
-
均值归一化。需要计算出所有特征的均值,然后令$x_j=x_j-u_j$。如果特征是在不同的数量级上,还需要将其除以标准差$\sigma^2$
-
计算协方差矩阵:$\Sigma=\frac{1}{m}\sum_{i=1}^{n}(x^{(i)})(x^(i))^T$
-
计算协方差矩阵的特征向量(奇异值分解[U,S,V]=svd(sigma))
-
选取U的前k列组成新的矩阵Z,即降维后的结果
主成分个数k的选择
使用建议
-
不要使用PCA去解决过拟合问题Overfitting,还是使用正则化的方法(如果保留了很高的差异性还是可以的)
-
只有在原数据上有好的结果,但是运行很慢,才考虑使用PCA
协同过滤
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
协同过滤是电子商务推荐系统的一种主要算法。